
Revisiting the Semantic Web Vision (in the Age of GenAI)
A conceptual view of distributed enterprise data connected by a shared “meaning layer,” enabling grounded GenAI with governance and trust.
For more than two decades, the Semantic Web promised a world where data could be shared and understood across organizations and systems; where meaning traveled with information, not just the bytes. If you’ve been in enterprise data long enough, you’ve probably heard some version of the punchline: “Great idea, but it never happened.”
That’s only half true.
The original Semantic Web vision wasn’t wrong; it was early. It assumed the web (and enterprises) would voluntarily converge on shared vocabularies, publish machine-understandable meaning everywhere, and maintain consistent identifiers over time. In practice, incentives were misaligned. Organizations guarded data. (Afterall, it’s the new gold!) Standards felt heavy. Tooling was uneven. And most teams had more immediate problems than global interoperability.
What’s changed isn’t the core idea; it’s the environment it must operate in. Today, enterprise data is inherently distributed across clouds, regions, SaaS platforms, partner ecosystems, and edge environments. The pressure isn’t “make the web smarter.” It’s “make enterprise AI reliable” – without assuming you can centralize everything first.
GenAI can produce fluent answers from messy data, but it struggles with grounding, consistency, provenance, and trust. Those are exactly the types of problems the Semantic Web community sought to solve. The “why now” isn’t philosophical anymore. It’s operational: if you want AI that stands up in production, you need a stronger layer of meaning that works across distributed systems.
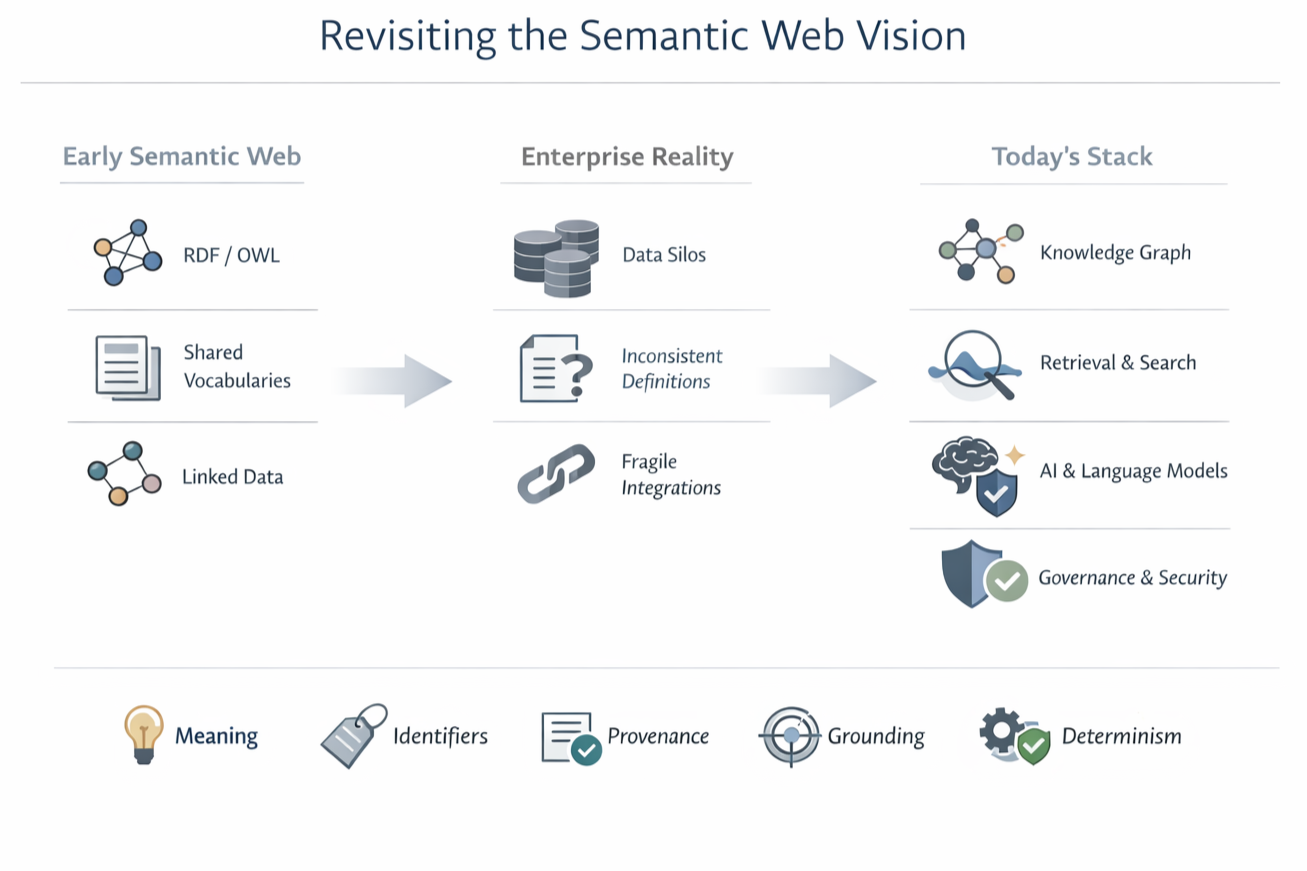
The evolution of the Semantic Web vision: from early standards (RDF/OWL, shared vocabularies, linked data), through enterprise reality (silos, inconsistent definitions, fragile integrations), to today’s stack (knowledge graphs, retrieval/search, language models, and governance) with the core requirements for trustworthy AI: meaning, identifiers, provenance, grounding, and determinism where needed.
What the Semantic Web got right (and why it matters even more in distributed enterprises)
1) Meaning is infrastructure
Enterprises don’t just need data integration; they need meaning integration. When two systems both say “customer,” do they mean the same thing? Is a “facility” the same as a “site”? Does “active” mean “logged in within 30 days,” “has an open contract,” or “not archived”?
The Semantic Web insisted that explicit semantics – definitions, relationships, constraints, and identifiers – are not a nice-to-have. They’re the only scalable way to keep systems coherent as complexity grows.
2) Identifiers matter more than storage
A key insight of the Semantic Web is that stable identifiers (for people, assets, products, documents, policies, concepts) are what allow systems to connect over time. Storage systems change. Applications come and go. APIs get rewritten. But identifiers – done well – become the connective tissue.
In a distributed world, this matters even more: when the data stays where it is, identity and meaning are what travel.
3) The graph model fits reality
The world isn’t naturally tabular. Enterprises are networks of relationships: suppliers, parts, regulations, risks, people, processes, entitlements, incidents, controls. Semantic technologies were always pointing toward graph-shaped truth, even when most implementations were forced back into tables for convenience.
Where the Semantic Web struggled (and what looks different now)
1) “Everyone will publish RDF” was the wrong adoption model
The web didn’t become fully machine-semantic – and enterprises won’t either, all at once. The practical path is incremental: start where semantics creates leverage (search, interoperability, analytics, AI grounding), then expand.
More importantly: modern enterprises don’t need to “convert everything into RDF” to get semantic benefits.
A more scalable pattern is this: distributed sources keep their native storage models and instead expose semantic endpoints – interfaces that map local structures to shared concepts. In this model, the meaning lives in the interface (the ontology + mappings + constraints), not necessarily in the physical storage format.
2) Ontologies felt like a big upfront commitment: so treat them as distributed products
Many teams experienced semantic modeling as academic or brittle. The modern approach is pragmatic:
Model just enough to support the outcomes you need
Keep the semantic layer modular and versioned
Treat vocabularies as living assets, not one-time documentation
And in distributed enterprises, a single monolithic “enterprise ontology” rarely works. What scales is distributed ontologies:
Domain ontologies owned by the teams closest to the meaning
Shared upper vocabularies and identity conventions to connect domains
Explicit mappings/alignment where concepts overlap
Versioning and governance that treats semantics as a product (with change management)
3) Data gravity isn’t solved by centralization: it’s managed by colocation + federation
Centralization can help in some cases, but modern architectures increasingly optimize for data colocation: keep data close to where it’s produced and consumed (for latency, sovereignty, cost, and operational ownership) and use federation to assemble cross-domain answers when needed.
This is where classic Semantic Web ideas become directly practical: federated query patterns, such as those popularized by W3C SPARQL federation, offer a blueprint for composing results across multiple semantic endpoints. The enterprise version of the idea is: query and reasoning “travel,” rather than forcing data to move everywhere by default.
The new center of gravity: semantic foundations for trustworthy AI across distributed data
GenAI raises a new question: What does the model know, and why should we believe it?
In distributed environments, the question sharpens: Which systems contributed to this answer? Under which definitions? With what permissions and policy constraints?
A well-implemented semantic foundation (applied across semantic endpoints and federated access) can provide:
Grounding: linking generated answers to authoritative sources – even when distributed
Disambiguation: resolving “which customer / which facility / which contract” across domains
Consistency: enforcing aligned shared definitions across business units
Provenance: tracing facts to systems of record and policy constraints
Explainability: showing the path of relationships behind a conclusion
Determinism where needed: mixing rules, constraints, and validations with LLM flexibility
This is the key storyline shift: the Semantic Web wasn’t only about machines understanding information. It was about making meaning explicit enough that systems can coordinate reliably – and humans can trust the results.
What “Semantic Web” looks like today (without the baggage)
We see the modern expression of the vision in patterns like:
Enterprise knowledge graphs used as an interoperability layer (not always a central store)
Data products and data mesh backed by shared semantics
Industry ontologies applied selectively (not dogmatically)
Federated interoperability across partners where it drives outcomes
AI-ready semantics designed for retrieval, grounding, and policy enforcement
In other words: the original vision didn’t disappear; it localized. It moved from the open web into the enterprise, where the incentives are clearer and the outcomes are measurable.
But there’s still a gap teams run into once the meaning layer exists, which is translating semantics into repeatable, governed execution, especially when decisions and actions span distributed systems. Establishing shared meaning is only the first step. Once systems can reliably interpret entities, relationships, and constraints, the next challenge is coordination: how decisions are decomposed, actions are authorized, and workflows are executed under policy. We explore this progression from semantic foundation to agent orchestration and bounded autonomy in a companion piece on knowledge-governed execution.
A pragmatic path forward: from meaning → semantic interfaces → federated access → grounded AI → governed execution
The practical evolution looks like this:
Establish an actionable meaning foundation (shared definitions, identifiers, relationships, constraints, provenance)
Publish meaning at the interface (semantic endpoints + mappings + constraints), without forcing a single storage format
Use federated query patterns to assemble cross-domain context when needed (optimize colocation; federate the rest)
Ground retrieval and AI outputs in authoritative sources with traceability and policy enforcement
Extend semantics into orchestration and execution so outcomes are repeatable, observable, and auditable
The theme is compounding value: semantics first improves understanding, then improves trust, and then improves operational behavior – without requiring centralization as a prerequisite.
What Crown Point does: making semantics operational with KCEF
At Crown Point Technologies, we treat “semantics” as more than a modeling exercise. Through our Knowledge-Centric Engineering Framework (KCEF), we help organizations turn shared meaning into verifiable, outcome-oriented behavior, and without forcing a rip-and-replace modernization.
KCEF is built around a simple separation of concerns: what the environment means vs. how outcomes get achieved. That distinction helps close the execution gap; where teams have plenty of data and AI insight, but still rely on manual coordination, brittle workflows, and inconsistent definitions under pressure.
1) Knowledge layer: an actionable meaning foundation (built for distributed reality)
We design and implement an actionable meaning layer using ontologies and knowledge graphs – capturing shared definitions, relationships, constraints, policies, and provenance in a form that can be used at runtime (not just documented).
Crucially, this doesn’t require every source to store data in RDF. Instead, KCEF supports patterns where distributed systems expose semantic endpoints aligned to shared concepts, so meaning is enforced at the interface while teams retain local autonomy over storage and operations.
2) Orchestration layer: policy-aware coordination across endpoints
Next, we connect that meaning layer to real operational workflows. KCEF uses semantic descriptions and policy to coordinate work more consistently and adaptably – whether through conventional workflow engines, rules/constraints, or agent-assisted planning that decomposes goals into feasible steps within authority and risk boundaries.
3) Execution fabric: governed action with resilience, observability, and auditability
Finally, we help operationalize a resilient, policy-governed execution fabric – the runtime that actually invokes actions while enforcing guardrails. This is where automation becomes accountable: authorization, constraint enforcement, retry/failover patterns, monitoring, and provenance and audit trails are embedded into execution so outcomes are defensible and learnable.
Trust and assurance: where GenAI becomes production-grade
KCEF treats trust as an architectural property, not a hope. We incorporate deterministic validation and constraint checks, traceability from inputs to actions, and semantic grounding so recommendations and decisions can link back to facts, rules, and sources. This is how you scale AI-driven behavior without relying on “AI magic.”
A pragmatic adoption path (not a big-bang transformation)
KCEF supports incremental adoption:
Phase 1: Semantic enablement
Phase 2: Agent-assisted orchestration
Phase 3: Governed autonomy at scale
The Semantic Web vision didn’t fail. It waited for a reason.
AI is that reason – and in a distributed enterprise, semantics at the interface plus federated access is how the vision becomes practical.
Key takeaways
The Semantic Web didn’t “fail” – it arrived early; today’s distributed data reality and AI trust requirements make semantics operationally necessary.
Centralization isn’t the goal: optimize colocation for performance, sovereignty, and ownership, and use federation to answer cross-domain questions.
Data doesn’t need to be stored in a single format: systems can keep native stores and expose semantic endpoints where meaning is defined in the interface.
Distributed ontologies scale better than monolithic models: local domain ownership plus shared identifiers and mappings enable interoperability.
Federated access improves grounding, provenance, and consistency for analytics and GenAI – by composing context from authoritative sources.
Trustworthy AI requires governance and “determinism where needed”: policy enforcement, traceability, and auditability across the full path from query to output.